Creative Bot Bulletin #3
By Yorick van Pelt
A NOTE FROM THE EDITOR
Nice to meet you! Long time reader, first time writer. I’m excited to tell you
about everything that happened since the last newsletter, since progress in
the generative AI world seems to be faster than ever. Enjoy!
—Yorick
Featured
In this section: Anthropic’s training approach, steering GPT-2, AI mind reading, Lakera’s Gandalf game
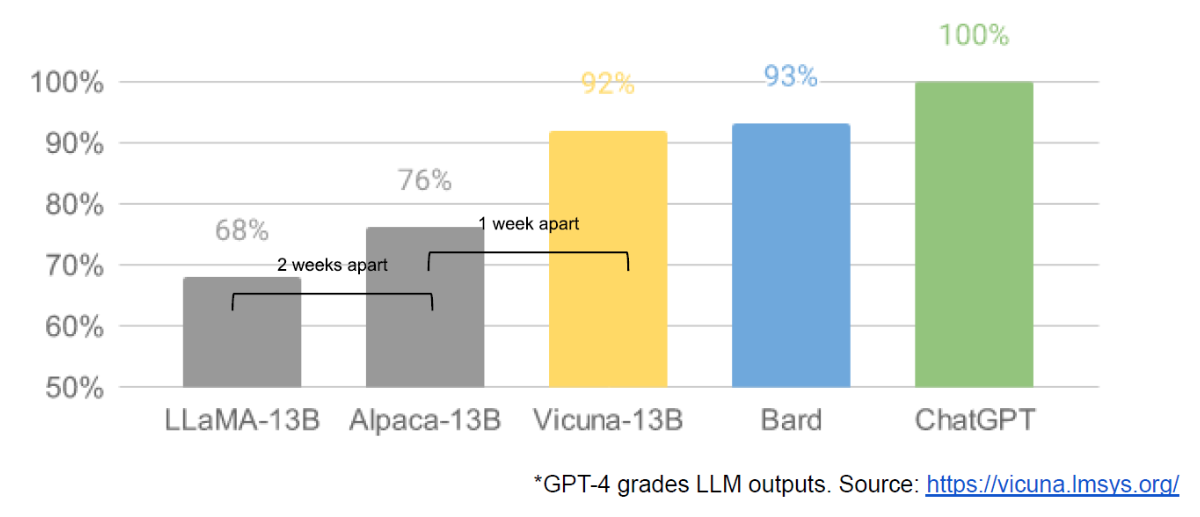
Leaked google memo : We Have No Moat, And Neither Does OpenAI by Googler Luke Sernau.
One of the clearest illustrations of the rapid pace of advancement is this leaked memo, describing the rapid progress in the world of open-source LLM’s and Google’s internal response to it. The timeline is very helpful in understanding what happened up to April 15th.
The most interesting quote, to me: “Responsible Release: This one isn’t “solved” so much as “obviated”.” I think this summarizes the state of AI safety quite well: Google was holding back the release of their language model in order to focus on alignment and safety, but Meta’s entirely unaligned LLaMa model, with similar capabilities, leaked to the general public in the meantime. Anyone can use this model to achieve the use cases Google was hoping to avoid.
In the month since this memo was written, quite a bit happened:
- Google opened Bard to the general public. I had fun talking to it, you should definitely try it out (use a VPN if you are not in a supported country).
- The new company Together came out with the RedPajama dataset and models, which can be fully replicated at home (or, well, the cloud) and can be used in commercial settings.
- AI company MosaicML released the open-source MPT-7B. With the base model, they claim to match the quality of Meta’s LLaMA-7B model, the best open-source model in that size so far.
Stay tuned for our upcoming blog post about the current state of open-source LLMs!
Creative AI and generative AI
In this section: Anthropic’s training approach, steering GPT-2, AI mind reading, Lakera’s Gandalf game
Anthropic: Claude’s Consitution. Currently, training language models to listen to instructions uses reinforcement learning with human feedback (RLHF) which requires a lot of input from humans. Maybe we can do better by having the AI evaluate itself while it’s training. Psychiatrist Scott Alexander has a great summary, comparing it to Cognitive Behavioral Therapy and self-reflection in humans.
Steering GPT-2-XL by adding an activation vector, research from Berkeley’s Center for Human-Compatible Artificial Intelligence, which tries to steer GPT-2 output by modifying the activation in it’s hidden layers. This produces fascinating results, and shows us additional ways to steer models to do the things we want.
AI mind reading
For quite a number of years, researchers have been trying to extract thoughts from human brains non-intrusively using fMRI and some data processing. A recent project from the University of Texas has used the recent advances in transformers to train a better decoder, which can read the thoughts of volunteers inside an fMRI machine (with their conscious cooperation), after they spent 16 hours training on specific people.
Some other researchers have focused on extracting images instead of thoughts, and recent efforts have started to include Stable Diffusion to make the data more appealing. I’m not personally a fan, since this makes the research seem much more impressive than it is, while the actual extracted data is highly susceptible to overfitting.
Gandalf 🧙
One of my favorite links from the past month is Lakera’s Gandalf game. Try to extract the password from an LLM with increasingly difficult safety mechanisms. There’s a new bonus level 8.
I’m quite jealous of the data Lakera must be gathering from this for their Lakera Guard product. Creating this game is a brilliant idea: fun to play for us, and useful for them.
Video Games

The Talos Principle is one of my favorite video games, a first-person puzzle game from 2014, with a philosophical narrative. I first played this a couple of years ago, but it’s as relevant as ever. The player is a robot, tasked with solving a variety of reasoning puzzles. The puzzles stay interesting and challenging, and the narrative is engaging from start to finish.
Datakami news

Media appearances
We contributed to a recent web video for the Dutch national news agency NOS: “how you train AI (For free)”. The video explains a crucial but often hidden aspect of Artificial Intelligence, namely the process of collecting data for training (and correcting) AI systems like ChatGPT. The video explains the behind-the-scenes work that is done by countless of human contributors: our unpaid contributions like filling in captchas, and efforts by underpaid clickworkers on crowdsource platforms.
We also joined editors of two children's TV shows to help brainstorm ideas for their episodes: De Dikke Data Show (VPRO) and Klaas Kan Alles (KRO-NCRV).
Thank you for reading! If you enjoyed this newsletter, consider forwarding it to a friend. Follow us on LinkedIn for more frequent updates.
This newsletter has been created using AI Influence level 1: Human Created, Minor AI Assistance.
More like this
Subscribe to our newsletter "Creative Bot Bulletin" to receive more of our writing in your inbox. We only write articles that we would like to read ourselves.